开源和闭源AI的差距,进一步被这家中国公司缩小了。
近日,被称为"AI界拼多多"的中国人工智能初创公司深度求索(DeepSeek)发布了全新大模型DeepSeek-V3(下称V3)并同步开源。该模型在Aider多语言编程测试排行榜中,已超越Anthropic的Claude 3.5 Sonnet大模型,仅次于榜首的OpenAI o1大模型。
开源No.1,多方面追平闭源大模型
DeepSeek是知名私募巨头幻方量化旗下的人工智能公司,根据DeepSeek公布的测试结果,其运行了多项基准测试来比较性能,V3模型已明显优于包括Meta公司的Llama-3.1-405B和阿里云的Qwen 2.5-72B等一众领先开源模型。在大多数基准测试中,它甚至部分超越了OpenAI的闭源模型GPT-4o。

Deepseek-V3在多方面超越、追平各种开源、闭源大模型。Deepseek
首先是百科知识上,V3的知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)水平相比前代 DeepSeek-V2.5 (下称V2.5)显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。长文本测评方面,在DROP、FRAMES 和 LongBench v2 上,V3 平均表现超越其他模型。
此外,V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非o1类模型,并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
值得注意的是,V3在中文和数学相关基准测试中表现尤为突出。
在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,V3大幅超过了所有开源闭源模型。在中文能力上,V3 与 Qwen2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
训练成本极低
按照美媒Venture Beat的说法,虽然V3已成为市场上最强大的开源模型,但其训练成本却非常非常低。
通过在上一代DeepSeek-V2上的成功验证,V3沿用了可以大幅降低显存占用的MLA(多头潜注意)和DeepSeekMoE(混合专家)架构,其具有6710亿参数,每次推理激活370亿参数,这种方法确保了高效的训练及推理。在训练阶段,DeepSeek使用了多种硬件和算法优化,包括FP8混合精度训练框架和用于管道并行的DualPipe算法,以降低训练成本。
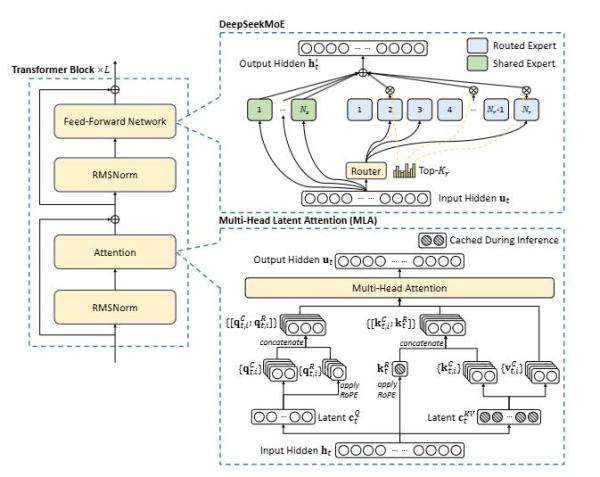
V3基础架构,DeepSeek创新的MLA被用于高效推理,DeepSeekMoE则用于经济训练。DeepSeek论文
DeepSeek声称,V3 实现了极高的训练效率。在约278.8万个英伟达 H800 GPU小时内完成了V3的整个训练,假设GPU的小时租金为2美元,总成本就是约为557万美元。这远低于通常用于预训练大语言模型动辄上亿美元的成本,比如Llama-3.1的预训练成本估计就超过5亿美元。
DeepSeek还通过算法和工程上的创新,使V3的生成吐字速度从20TPS大幅提高至60TPS,相比V2.5模型实现了3倍的提升,在处理多模态数据和长文本时表现突出。而随着性能更强、速度更快的V3更新上线,DeepSeek的模型API服务定价也调整为每百万输入tokens 0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens 8元。
量化基金转型人工智能
公开资料显示,在DeepSeek背后是量化私募巨头幻方(High-Flyer Quant),也是大厂外唯一一家储备上万张英伟达 A100芯片的公司。幻方成立于2008年,总部位于中国杭州,专注于利用数学、统计学和计算机技术进行金融市场的量化分析和交易。
自2023年四季度以来,A股市场不断下行,而利用数学模型和计算机程序等技术手段进行投资决策的量化基金曾被作为"罪魁祸首"受到舆论的冲击,这也让幻方旗下基金表现一直落后于沪深300指数4个百分点。
不过,随着今年5月DeepSeek-V2发布,幻方量化却成功转型为人工智能先驱,其超低价格甚至引发了国内大模型的价格战,DeepSeek也被迅速冠以"AI界拼多多"之称。这反映出百度和阿里巴巴等科技巨头,尽管在生成式人工智能领域已处于领先地位,但仍需要面对着来自新玩家的激烈竞争。
幻方创始人梁文锋此前曾回应称,DeepSeek定价原则就是不贴钱,但也不赚取暴利。只是让他也没想到的是,DeepSeek的定价却让各大厂商纷纷降价,然而DeepSeek自身反而却是有利润的。
"字节是第一个跟进的,其旗舰模型降到和我们一样的价格,然后触发了其它大厂纷纷降价",梁文锋解释说,"因为大厂的模型成本比DeepSeek高很多,所以DeepSeek没想到会有人亏钱做这件事,最后就变成了互联网时代的烧钱补贴的逻辑。"
梁文锋认为,更多的投入并不一定产生更多的创新,否则大厂可以把所有的创新包揽了。










