Qwen2.5-Max超越deepSeek V3这个事情背后有个故事,早在春节前夕,DeepSeek火爆全球之后,阿里的算法专家也一直在研究,后来终于找到了关键点,deepSeek的底座用的是Moe模型,阿里的Qwen用的还是Moe模型。甚至Meta的LLaMA的底座也是。

MOE模型(混合专家模型)是AI圈热门的大模型架构,这个架构的厉害之处,它只需要激活必要的参数来处理输入的数据,主动减少计算需求,主动计算需求减少,自然节约算力,算力节约了就能节约芯片数量,使得计算成本得以大幅降低,推理性能也有所改善。
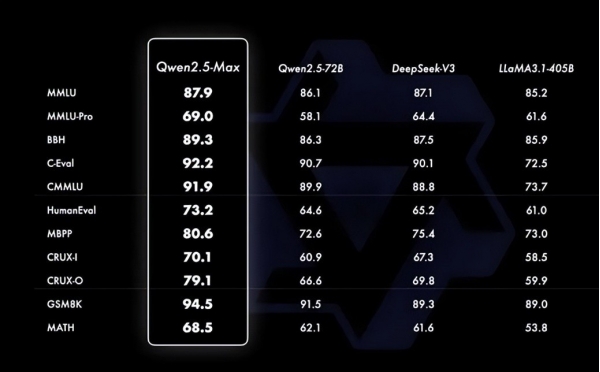
因此,阿里工程师醒悟过来,为什么DeepSeek能火爆全网、让整个硅谷科技圈睡不着觉,而Qwen不能? 要知道,在Moe架构领域,Qwen是规模最大的那一个,又有20万亿Tokens(相当于1.5亿本小说)。于是阿里的工程师加班加点,甚至把车票都退了,终于在大年初一,发布了新的模型Qwen2.5-Max。
可能就是阿里的新模型Qwen2.5-Max让苹果开始放弃百度转向了阿里。
因为Qwen2.5-Max这个版本的亮点在于,超大规模的MoE模型,预训练数据超20万亿Tokens,全面超越DeepSeek V3,性能更强,更节约算力。需要注意的是,阿里Qwen 2.5Max超过了DeepSeek-V3,没有超过deepSeek R1。